
Machine Learning for Energy Optimisations
My name is Munaaf Ghumran, and I am a third year student at Bristol University working on the Machine Learning analysis for MAGEEC.
Finding the Best Flags for a Given Program
The Machine Learning will be used to automatically predict the best set of flags for a given program, based on previously learnt data.
Research began into the Machine Learning tools to be used in MAGEEC based upon the existing platform created for MILEPOST. Understanding the approach used there was used as the starting point because replicating that would ensure that there is a reference to work against — and it works.
I have actually been fortunate enough to communicate with the team that worked on MILEPOST in order to be able to gain further insights into their reasoning behind methods.
Methods
There are a few methods that could be used, and it is my job to analyse which ones would be most effective in this project. Some methods are supervised and some are unsupervised — these are the two different types of learning in Machine Learning. And anyone wondering how to become an ml engineer must know both the types of learning.
Supervised learning is where we train/test the data and get actual results; so we can feed in the correctly labelled data to be learnt, apply an algorithm and test it. Unsupervised learning is more of analysis into any pattern/structure to the data that we are going to give to the algorithm. For my summer project I will look at both types, starting with unsupervised before testing out some models with supervised learning.
Supervised Learning
At this stage I am looking for what models could be used to train the data we are working on. So currently I am looking into the general benefits for a variety of learners, before reducing that to a select few that can then be compared and tested. We know that with MILEPOST they used decision trees and k-nearest neighbour (kNN) with leave-one-out cross-validation, so already we have a few methods that are proven to work, and then the task is to see if any others perform as well as these.
Others include SVNs and various regression models such as neural networks. These are all going to be investigated for suitability with this task.
Another point to mention here is the type of validation performed on the models, that is to say the check of how accurate it really is. MILEPOST used leave-one-out validation, which is a form of cross fold validation that tests each instance based on every other instance to minimise bias and variance.
There is another standard validation technique called 10-fold cross-validation, which I have used before. 10-cross is a variant where the entire data set is split into 10 equal parts, and each of these parts are then used as the test set against the 9 other parts consecutively until all 10 parts have been the test set. Then the average over all 10 is taken for error rates or accuracy, to show how well it performs.
Although similar, some studies (Efron, 1983) have shown that 10-fold has slightly less variance. For this reason I believe we should use it in MAGEEC, and it should be less computationally expensive not having to test against almost the whole data set each time.
Unsupervised Learning
PCA
One method that is in research is the use of Principal Component Analysis (PCA) into the set of features used by MILEPOST to see if there is a simpler way to represent 56 features. The aim for this is to be able to represent those 56 features in terms of perhaps 4-5 features, reducing the hyperspace from 56 dimensions to 4 or 5.
One problem with research into PCA is that with 56 features, there would need to be a variety of programs and resulting feature vectors that cover a wide range of each type of feature, to have reliable analysis that doesn’t just arbitrarily focus on the features that would always be common in all programs and therefore throw away ones that just were not frequent in the set.
This brings around the issue of having a large enough data set of .c programs that the feature vectors can be obtained with by MILEPOST. It is relatively easy to find perhaps 30 or so programs that are common free benchmarks such as 2dfir blowfish sha… but to sufficiently test this hypotheses, at least 150 programs are likely to be required, or more. It is very difficult to find this number without having to buy a suite such as Embassy.
I looked into some open source benchmark suites such as CoreUtils for programs to run under MILEPOST to get more feature vectors, which is done on a per file basis. Unfortunately, CoreUtils is designed in a way that it actually isn’t possible to run the provided c files under gcc due to other dependencies – and the only way the files build are using the provided makefile. This makefile however is thousands of lines long, and each file needs to be run separately under MILEPOST, so it isn’t possible to set up a script for each file.
So at present we have insufficient programs to effectively reveal a good insight through PCA. To note from my brief analysis using 36 programs from MiBench and WCET: running PCA under MATLAB and WEKA resulted on those datasets with a reduction to 5 features, covering at least 99% of the variance in data. This result is shown here with a scree plot that shows there is almost no more variance left in the data after it is reduced to 4 to 5 components.
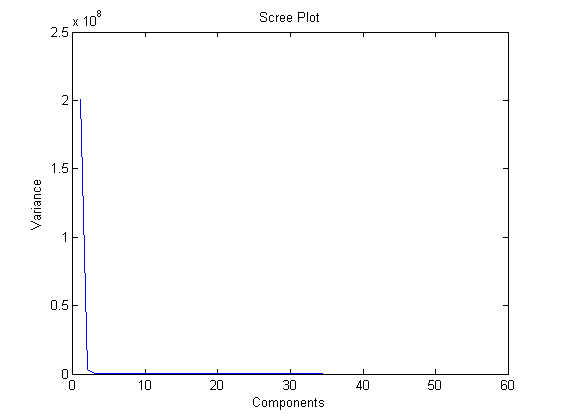
Why wasn’t PCA used for MILEPOST?
After contacting people who worked on MILEPOST, it became clear that the reason they did not employ the approach of PCA was because the system involved allowed automatic generation of features from the domain information. A point has been made by them too that there is a chance PCA may obfuscate a good feature — so perhaps instead of compressing these features down, there should be analysis on the quality of them. Having to analyse the quality of the features used currently would be another project in itself however, so although this is probably the better approach, there wouldn’t be a way to do this in the time available.
WEKA
The next stage is to begin to use data collected on programs so far to attempt to run a couple of learning algorithms to get an idea of which ones will perform the best. To do this, WEKA will be used as it is a good off-the-shelf system that has a variety of algorithms ready to use. This will give an insight into the types of learners that give the best results based on our inputs. It will be interesting to see which algorithms give good results, as I am expecting decision trees to do a good job with the added benefit of them being particularly fast.


")




Trackbacks & Pingbacks